Objetivo General
Es extender y adaptar esta aplicación base, añadiendo nuevas funcionalidades y demostrando tu habilidad para modificar y mejorar un sistema existente que debe permanecer desplegado y funcional en Azure.
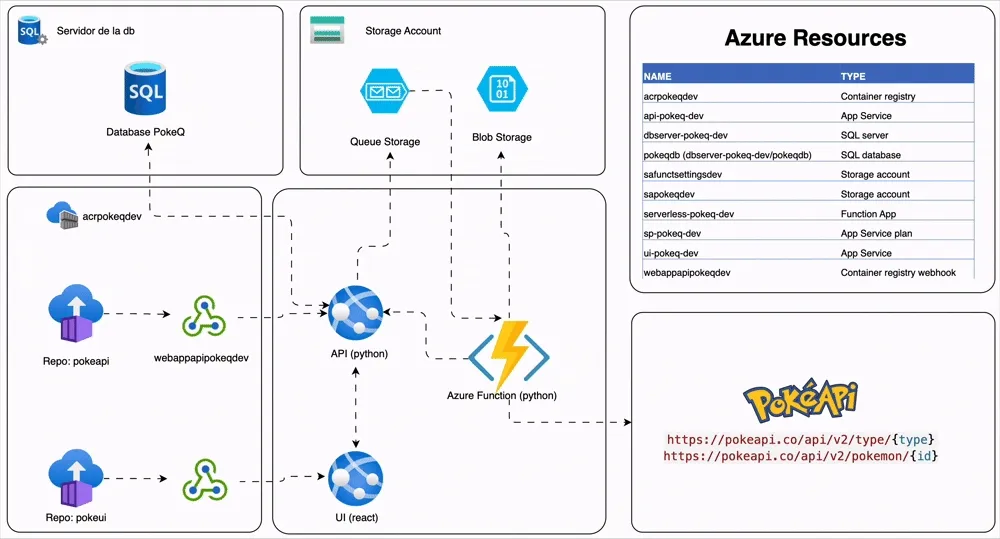
Contexto Tecnologico
-Frontend: Next.js (React)
-Backend: API Python con FastAPI desplegada en Azure App Service
-Proceso Asíncrono: Azure Functions (Python Queue Trigger)
-Base de Datos: Azure SQL Database
-Almacenamiento: Azure Blob Storage (para los CSV),
-Azure Queue Storage (para mensajes)
-API Externa: PokeAPI
-Infraestructura como Código (IaC): Terraform (implícito por la mención del repositorio)
Tarea 1: Implementar Eliminación Completa de Reportes
El primer paso para implementar la eliminacion fue crear el correspondiente endpoint:
{domain}/api/request/{id} <- METHOD_POST (Para el registro)Ese endpoint toma el id y hace una busqueda en la base de datos verificando si el registro existe Si el registro existe entonces ejecuta un metodo que ejecuta un query donde se elimina el registro, este metodo tambien envia un mensaje al queue DeleteQueue luego azure worker o azure function llamado serverless-pokeq-dev toma ese mensaje y procede con la eliminacion del blob file, el cual se hizo mediante el metodo .delete_blob() que esta incluido en el SDK de Azure.
Tarea 2: Enriquecer Reporte con Detalles del Pokémon
Al principio el funcionamiento de la API era el siguiente:
Se hacia una peticion GET a la API de PokeAPI
https://pokeapi.co/api/v2/type/{type} <- METHOD_GETen donde el parametro {type} es el tipo de pokemon del cual nosotros queremos la lista
La consulta a este endpoint nos devuelve la siguiente informacion:
- 1. Nombre del pokemon
- 2. URL del pokemon
- 3. slot
Para el nuevo funcionamiento: Se necesitaba extraer datos de la API de Pokémon desde dos estructuras diferentes:
- Lista básica: Con nombres y URLs de Pokémon
https://pokeapi.co/api/v2/type/{type} <- METHOD_GET- Endpoint detallado: Con stats y abilities tras hacer peticiones HTTP
https://pokeapi.co/api/v2/pokemon/{id} <- METHOD_GETInicialmente se cree funciones que mantenían la estructura de un diccionario de la forma:
data_dict = {
"name": "Pokemon",
"stats": {"hp": 39, "attack": 52, ...},
"abilities": [{"blaze": "blaze"}, ...]
}Sin embargo para poder dejarlo listo de un dataframe es necesario poder ‘Aplanar’ esta estructura
Recoleccion de toda la data
Proceso:
- Itera sobre lista de Pokémon
- Aplica extracción individual a cada elemento
- Maneja fallos individuales mediante un Try Catch sin romper el proceso completo
Aplanamiento de Datos
Problema: DataFrames/CSV no manejan bien estructuras anidadas
Los stats estaban guardados en un dict llamada “stats”. La solución fue romper el diccionario y poner cada stat directamente como una columna separada en la tabla. Es como si tuvieras una carpeta llamada “Calificaciones” con hojas sueltas adentro. En lugar de tener la carpeta, sacas cada hoja y las pones directamente sobre el escritorio, cada una con su propio lugar.
- Stats:
stats.hp→hp(columna directa)
# Antes
pokemon_data['stats'] = {"hp": 39, "attack": 52, "defense": 43}
# Después - Se promocionan al nivel principal
for stat_item in pokemon_data['stats']:
stat_name = stat_item['stat']['name'] # 'hp'
base_stat = stat_item['base_stat'] # 39
flat_data[stat_name] = base_stat # flat_data['hp'] = 39Para Abilities: Expandir horizontalmente
Las abilities eran una lista de elementos complejos (cada ability tenía nombre, si era oculta, y un número de slot). La solución fue crear múltiples columnas para cada ability: una columna para el nombre de la primera ability. Luego lo mismo para la segunda ability, y así sucesivamente.
- Abilities: Array complejo → múltiples columnas (
ability_1_name,ability_1_name, etc.)
# Antes
"abilities": [
{"name": "blaze", "is_hidden": false, "slot": 1},
{"name": "solar-power", "is_hidden": true, "slot": 3}
]
# Después - Una columna por cada atributo de cada ability
abilities = extract_abilities(pokemon_data['abilities'])
for i, ability in enumerate(abilities, 1):
flat_data[f'ability_{i}_name'] = ability['name'] # ability_1_name: blaze
flat_data[f'ability_{i}_name'] = ability['name'] # ability_1_name: blazeManejo de Abilities Variables
Problema: Pokémon tienen diferente número de habilidades
Solución:
# Columnas dinámicas por habilidad
ability_1_name,
ability_2_name
# + columnas resumen
all_abilities: "blaze, solar-power"
total_abilities: 2Organización de Columnas
Se estableció un orden lógico:
- Identificación: name, url
- Stats de combate: hp, attack, defense, etc.
- Resumen de abilities: total_abilities, all_abilities
- Detalles de abilities: ability_1_name, ability_2_name, etc.
name -> url -> hp -> attack -> defense -> special-attack -> special-defense -> speed -> total_abilities -> all_abilities -> ability_1_name -> ability_2_name -> ability_3_name -> etc
DataFrame
El DataFrame nos permite organizar los datos de una manera tabular, lo que nos beneficia porque queremos exportar un CSV
Con los datos previamente aplanados y las columnas tambien ordenadas solo ulilizamos la libreria Pandas creamos el dataframe y poblarlo a partir de nuestra lista.
Exportación
Para la exportacion se utilizo el metodo previamente creado y solo fue cuestion de pasarle el nuevo blob_file
Manejo de Errores
- Peticiones HTTP con try-catch
- Continúa procesando aunque falte un Pokémon
- Mensajes informativos de progreso
Tarea 3: Reportes con Muestreo Aleatorio
Permite al usuario especificar un número máximo de registros aleatorios a incluir en el reporte.
Frontend
Utilizando la libreria radix-ui se utilizo el componente label-input
para obtener el tamaño del sample desde el lado del clientes
Backend
Se modifico el endpoint http://{domain}/api/requests/{type}/{sample_size} para
obtener mediante un path variable el numero de registros requeridos por el usuario
Se modifico el modelo en pydantic de manera que este tuviera un nuevo campo llamado
sample_size que es un numero entero mayor o igual a cero (0) Se hizo la modificacion
correspondiente en la base de datos y tambien en el procedimiento almacenado para
seguir utilizando esa misma funcionalidad solamente con pequeños ajustes
Worker - Azure Function
Mediante la funcion get_request(id) obtenemos un json con los datos de la solicitud,
incluyendo el sample size, aprovechamos esto para para validar si el tamaño deseado
de la muestra es menor a numero de registros que contiene el tipo de pokemon requerido
por el usuario, si llega a ser menor entonces utilizamos la funcion ‘Recortamos’
el arreglo con la lista de pokemones antes de que se agreguen todos los detalles
que utilizaremos en el dataframe de la siguiente manera: python sample_pokemon_list = pokemon_list[:random.randint(1, list_len)] si la muestra requerida por el usuario
llega a ser mayor que la lista obtenia desde la API de Pokemon entonces devolveremos
todos los pokemones del mismo tipo que esten disponibles en la API
Resultado final en el CSV
name,url,hp,attack,defense,special-attack,special-defense,speed,total_abilities,all_abilities,ability_1_name,ability_2_name,ability_3_name
charmander,https://pokeapi.co/api/v2/pokemon/4/,39,52,43,60,50,65,2,"blaze, solar-power",blaze,solar-power,
charmeleon,https://pokeapi.co/api/v2/pokemon/5/,58,64,58,80,65,80,2,"blaze, solar-power",blaze,solar-power,
charizard,https://pokeapi.co/api/v2/pokemon/6/,78,84,78,109,85,100,2,"blaze, solar-power",blaze,solar-power,🔗 Enlaces importantes:



